
USAY Database Operation Series
USAY Data Tunnel
Introduction
Relationship databases have long been the primary solution for enterprises to store data. In many scenarios, relational libraries, as the most important part of production, are absolutely intolerable, but the data that exists in relational databases needs to be synchronized to other platforms. How to synchronize incremental data from the production of online databases to other platforms is an important requirement without compromising performance.
Product Overview
In order to adapt to the needs of the big data era, combined with years of experience in database research and development, the successful development of fully independent intellectual property rights of the USAY Data Tunnel can help customers without affecting the performance of the production library, the incremental data synchronization to other heterogeneous platforms.
Product Advantages
USAY Data Tunnel can help users solve the challenges of databases.
Scenario 1: Oracle Production Library, alternative library runs in parallel.
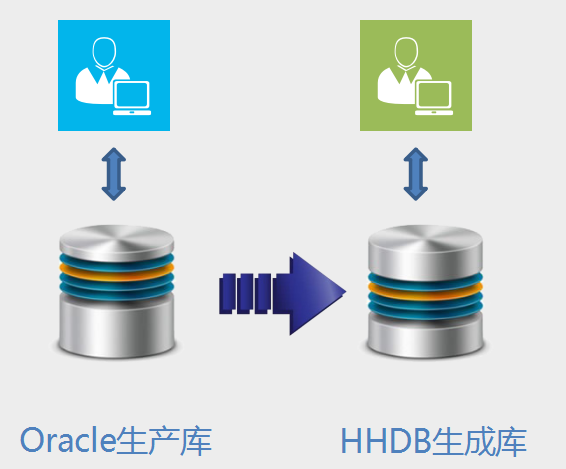
– Challenges in going to IOE: Oracle’s data is synchronized to an alternative library. Cannot add an agent to production.
Scenario 2: Incremental data in the production relational library - big data platform increment.
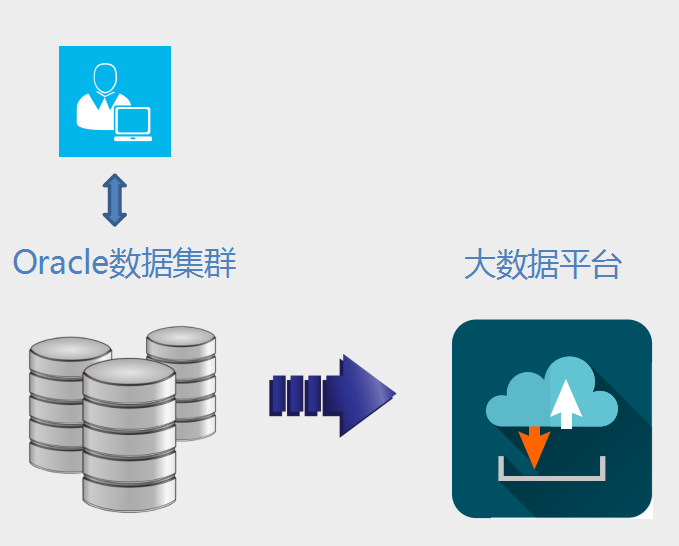
– Oracle performance is not affected.
– Oracle security cannot be affected .
– Big Data platform and Oracle data structure inconsistent.
– Incremental data cannot be lost or duplicated.
USAY Data Transfer Platform
Introduction
When faced with migration to a new storage platform or consolidation of multiple environments, the migration of outdated, obsolete, and age-old data is undoubtedly a complex and environmentally friendly process. Data center migration and consolidation tasks are common, especially at a time when data centers are growing at an average rate of 40 to 60 percent per year, leaving our data center managers with three choices: increasing data volume in the data center.
Date Center Migration Integration Methods
Data analysis is an analysis of metadata for unstructured user files. Data analysis enables efficient and cost-effective metrics (via NFS/CIFS/NDMP) by extracting critical metadata. The last modified/access date, data owner, location, size, and even duplicate content can be customized. This analytics software is very different from existing analytics access logs and network metadata solutions. This analysis software can drill down into files for data analysis, even analyzing a complete text outline if needed, and providing comprehensive information access to the file. When managing files, this is the only solution that provides the relevant knowledge background and the analytical tools and disposal capabilities needed to migrate data effectively.
The Technical Preparation of Data Transfer
Data transformation and migration usually includes several tasks: old system data dictionary finishing, old system data quality analysis, new system data dictionary collation, new and old system data differential analysis, the establishment of the new and old system data problem mapping relationship, the development of deployment data transformation and migration programs, the development of data transformation and migration process contingency plan, the implementation of the old system data to the new system transformation and migration work, check the integrity and correctness of the data after conversion and migration.
The process of data transformation and migration can be divided into three steps: extraction, transformation and loading. Data extraction and transformation are based on the mapping relationship between the old and new system databases, and the data difference analysis is the prerequisite for establishing the mapping relationship, which also includes the difference analysis of code data. The conversion step generally includes the process of data cleaning, data cleaning is mainly for the source database, the data that appears ambiguous, repetitive, incomplete, violation of business or logic rules and other issues to carry out the corresponding cleaning operation; Data loading is the extraction and transformation of result data loaded into the target database by loading tools or self-written SQL programs.
Data review includes the following steps:
- Data format check – check that the format of the data is consistent and available, and the target data requirements are number-type.
- Data length check – check the valid length of the data, and special attention is required for the field conversion of the char type to the varchar type.
- Interval range check – check that the data is contained in the defined interval of maximum and minimum values.
- Empty value, default check – check that the empty values defined by the old and new systems are the same, and that the definitions of empty values may vary from database system to database systems, requiring special attention.
- Integrity check – check the associated integrity of the data. If the code value of the reference is recorded, it is particularly important to note that some systems have removed the foreign key constraint spent in order to improve efficiency after a period of time in use.
- Consistency check – check the logic for data that violates consistency, especially systems that commit operations separately.
Choice of Tools for Data Transfer
There are two main options for the development and deployment of data migration tools, namely, developing programs on their own or purchasing mature products. Both options have their own different characteristics, and are subject to analysis on a case-by-case basis. Throughout the current domestic some large-scale projects, in the data migration is mostly the use of relatively mature ETL products. You can see that these projects have some common features, including: migration with a large amount of historical data, allowed for short downtime, facing a large number of customers or users, the existence of third-party system access, if the impact of failure will be very wide. It should also be noted that self-development programs are also widely used.
Today, many database vendors offer data extraction tools such as InfoMover for Informix, DTS for Microsoft SQL Server, and Oracle Warehouse Builder in 0raele. These tools address the extraction and transformation of data to a certain extent. However, these tools are largely unable to extract data automatically, and users need to use them to write appropriate transformation programs. For example, Oracle’s Oracle Warehouse Builder (OWB) data extraction tool provides features such as model construction and design, data extraction, movement and loading, metadata management, and more. However, OWB provides cumbersome processes, difficult maintenance, and not easy to use.
USAY Data Transfer Platform
USAY Data Transfer Platform is a relatively perfect set of products. USAY can extract data from multiple different business systems, from multiple platform data sources, complete conversion and cleaning, loaded into various systems, each step can be completed in graphical tools, the same flexible external system scheduling, providing specialized design tools to design conversion rules and cleaning rules, and so on, to achieve incremental extraction, task scheduling and other complex and practical functions. One of the simple data transformation can be achieved by dragging operations on the interface and calling some USAY predefined conversion functions, complex transformation can be achieved by writing scripts or combining extensions in other languages, and USAY provides debugging environment, which can greatly improve the efficiency of development and debugging extraction and conversion programs.
USAY Disaster preparedness System
Product Overview
In order to ensure a consistent and stable system running time, disaster preparedness is becoming more and more important, and the traditional disaster preparedness system in the sense of ordinary users to discourage. For example, Oracle uses its own RAC and DG high-availability clusters and disaster-tolerant methods such as OGG, and some other databases, such as MySQL and Postgresql, use third-party software LinuxHA, keepalived and other master-to-disaster preparedness switching methods.
According to the user experience, there are obvious many shortcomings and shortcomings, such as high server requirements configuration, deployment is extremely difficult and expensive technical support and so on. What users need is higher availability and lower costs.
USAY Disaster Preparedness Model
1. Master prepared mode
This is the primary prepared mode. The master prepared mode is based on the disaster preparedness mode of shared storage, mainly for database data files, log files, control files of one of the largest protection, that is, data redundancy, and shared storage is a naked device and file system isolation, so to ensure the security of the data, because the use of bare devices to avoid the Unix operating system this layer, data Disk directly to the database transmission, so the use of bare devices for I/O reading and writing database frequent applications can greatly improve the performance of the database system.
The disaster preparedness mode of shared storage, mainly for database data files, log files, control files of one of the largest protection, that is, data redundancy, and shared storage is a naked device and file system isolation, so to ensure the security of the data, because the use of bare devices to avoid the Unix operating system this layer, data Disk directly to the database transmission, so the use of bare devices for I/O reading and writing database frequent applications can greatly improve the performance of the database system. The master-prepared model developed by USAY is similar to Oracle’s RAC-based master provision model for shared storage, but Oracle RAC is not to mention that maintenance is difficult and expensive for technical support. Performance may not be effectively addressed.
2. Master dependent mode
Master dependent system is database flow replication, to achieve read-write separation. The master-dependent pattern developed by USAY is similar to the master-dependent mode of Oracle’s DG and MySQL stream replication.